Sentry Page Protection
Data Manipulation [11-18]
(In=) Option
The (in=) option identifies the input data sets when merging the data.
Again, let's take a look at the DS1 and DS2 data sets.
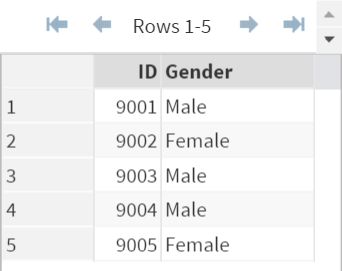
Data set: DS1

Data set: DS2
Again, we are going to merge the DS1 and DS2 data sets.
Example
proc sort data=ds1;
by id;
run;
proc sort data=ds2;
by id;
run;
data ds;
merge ds1 (in=a) ds2 (in=b);
by id;
run;
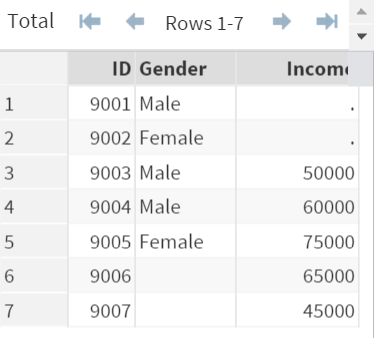
(In=a) Option
The (in=a) option is placed after the DS1 data set in the MERGE statement.

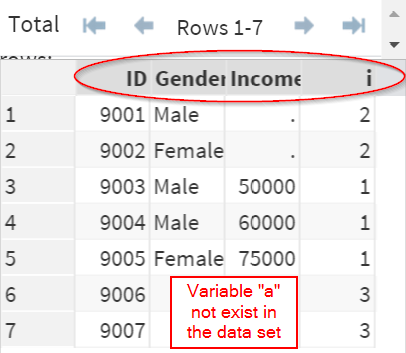
It creates a variable called "a" that is not visible in the data set.
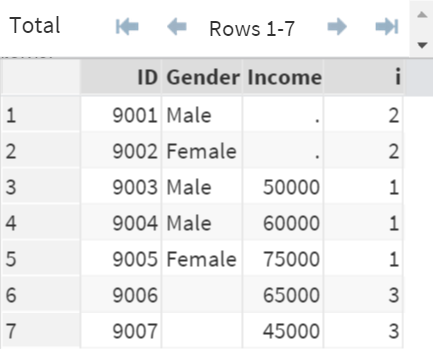
Not visible in the data set?
Yes, in fact, the variable "a" does not exist in the data set.
However, it exists in the data step.
That is, you can refer to this variable in your program.
However, it exists in the data step.
That is, you can refer to this variable in your program.

Default value of "a"
The variable "a" contains either a 1's or 0's (binary).
To see the value of "a", we must copy "a" into a variable that is visible in the data set.
Example
data ds;
merge ds1 (in=a) ds2 (in=b);
by id;
var1 = a;
run;
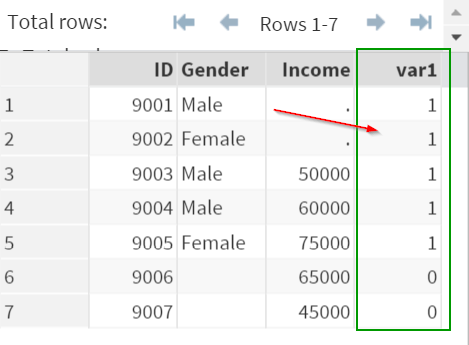
The variable Var1 is a carbon copy of "a".
It contains exactly the same data as "a".

The variable "a" flags whether the observation is contributed by a specific data set.

In this example, the variable "a" is associated with the data set DS1.
It is flagged as "1" if the observation is contributed by DS1.

The ID's (9001, 9002, 9003, 9004, 9005) are all contributed by DS1.
They are all flagged as "1".
On the other hand, the observations that are NOT contributed by DS1 (i.e. 9006 and 9007) are flagged as "0".
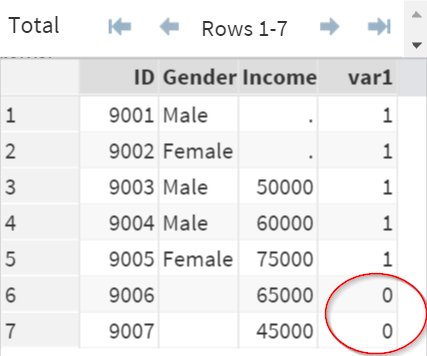
Identifying observations
Now that we know the values of "a" (and "b"), identifying the matching and unmatched observations becomes much easier.
Example
data ds;
merge ds1 (in=a) ds2 (in=b);
by id;
if a=1 and b=1 then i=1;
else if a=1 then i=2;
else if b=1 then i=3;
run;
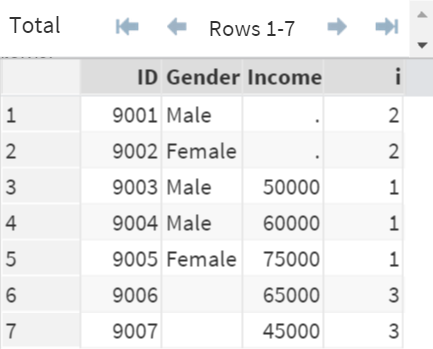
When both "a" and "b" are 1's, the observations are contributed by both DS1 and DS2 (matched observations).
These observations are flagged as 1 (i=1).
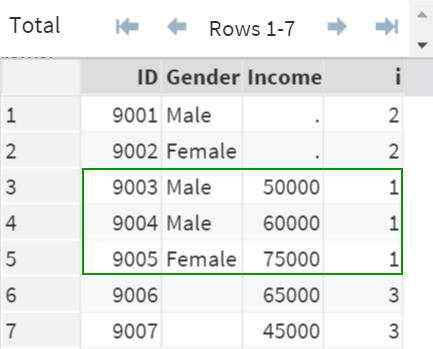
When the observations are not matching, and they are contributed by only DS1, the observations are flagged as 2 (i=2).
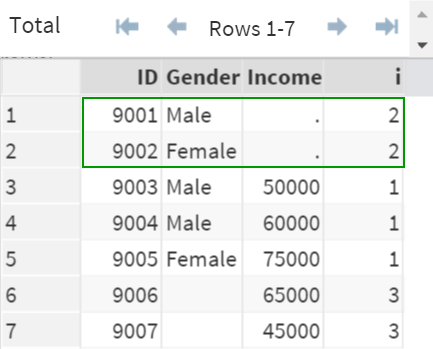
Similarly, when the observations are contributed by only DS2, they are flagged as 3 (i=3).
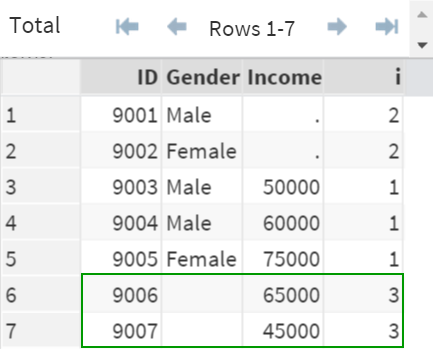
Overall, the observations are flagged into 3 groups:
- Matched observations (i=1)
- Unmatching observations from DS1 only (i=2)
- Unmatching observations from DS2 only (i=3)
Important Note
The conditional statements:
if a=1 and b=1 then i=1;
else if a=1 then i=2;
else if b=1 then i=3;
are the same as
if a and b then i=1;
else if a then i=2;
else if b then i=3;
In practice, it is more common to write the code as below:
data ds;
merge ds1 (in=a) ds2 (in=b);
by id;
if a and b then i=1;
else if a then i=2;
else if b then i=3;
run;
Exercise
Copy and run the ALLPOP and DROPOUT data sets from the yellow box below:
Copy and run the ALLPOP and DROPOUT data sets from the yellow box below:
The ALLPOP data set contains a list of 10 patients enrolled in a clinical study.
While the clinical study has been ongoing, some patients dropped out of the study due to various reasons.
The list of dropped out patients are stored in the DROPOUT data set.
Task
Create a new variable that flags the patient:
- 1 for current patient
- 2 for dropped out patient
Create any additional data set or variable if needed.
Need some help?
HINT:
Simply use the code covered in this session as a template. This should get you the correct results.
SOLUTION:
proc sort data=allpop;
by pid;
run;
proc sort data=dropout;
by pid;
run;
data allpop2;
merge allpop (in=a) dropout (in=b);
by pid;
if b then flag = 2;
else if a then flag = 1;
run;
Fill out my online form.