Sentry Page Protection
Data Manipulation [3-18]
Removing Duplicate Observations
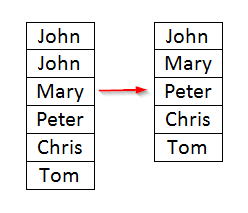
Duplicate observations affect your analysis results.
You can remove them by using the NODUPKEY option in Proc Sort.
Example
You can remove them by using the NODUPKEY option in Proc Sort.
Example
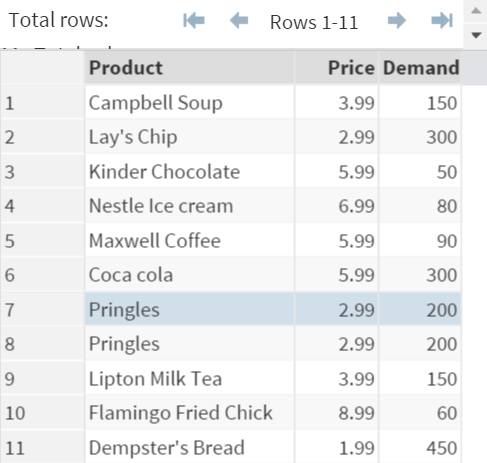
The SUPERMARKET data set contains 3 variables:
- Product
- Price
- DemandPerWeek
Pringles is a hot seller. However, it is also duplicated in the data set.
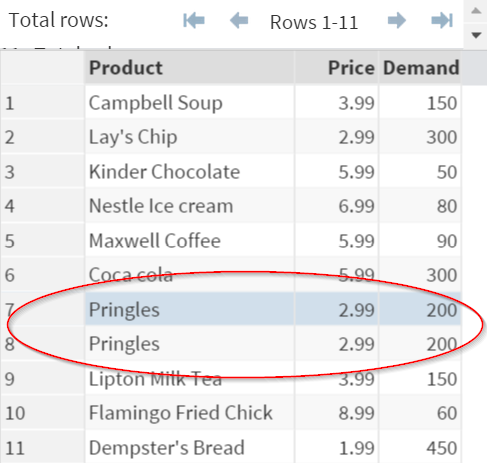
We can use the NODUPKEY option from Proc Sort to remove the duplicate observations.
Example
Proc Sort Data=Supermarket Out=Supermarket2 NODUPKEY;
By Product Price DemandPerWeek;
Run;
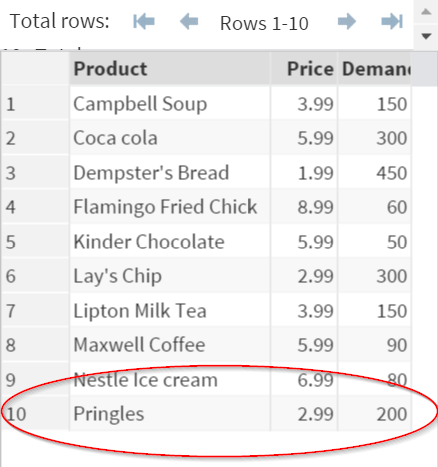
The data set is sorted with the duplicated observation (Pringles) removed.
The Log window also shows a note about the removal of the duplicated observation.
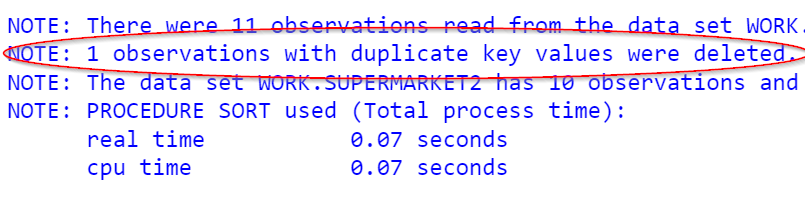
Note: the NODUPKEY option should be used with caution. Triple check the duplication before you remove them from the data set.
Exercise
Copy and run the INCOME data set from the yellow box below.
Copy and run the INCOME data set from the yellow box below.
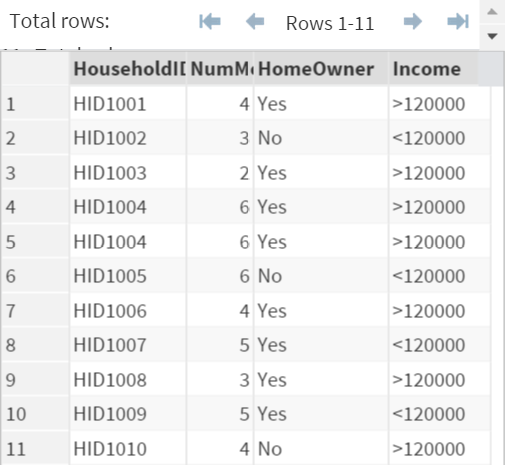
The INCOME data set contains 4 variables:
- HouseHoldID
- NumMembers
- HomeOwner
- Income
Remove any duplicate observation(s) from the INCOME data set.
Need some help?
HINT:
It is highly recommended to create a new data set when removing the duplication. Keep the original data set intact in case you need to go back to the source data.
SOLUTION:
Proc Sort Data=Income Out=Income2 NODUPKEY;
By HouseHoldID NumMembers HomeOwner Income;
Run;
Fill out my online form.