Sentry Page Protection
Proc Print [2-2]
SAS Base Exam
SAS Base Exam
Variable Label
When running the PRINT procedure, you can print the variable label as opposed to the variable name by adding the LABEL option.
Example
Copy and run the CARRIER data set from the yellow box below.
Example
Copy and run the CARRIER data set from the yellow box below.
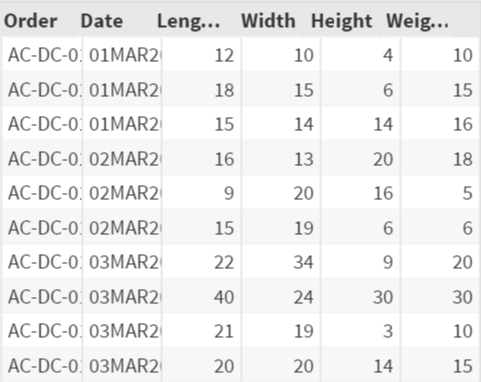
The LENGTH variable is currently assigned the label of "Length (inch)".
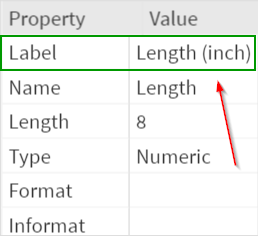
At the top of the data set, select "Variable Label" from the View menu:
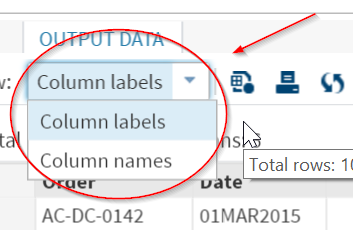
The data set will show the label instead of the variable name.
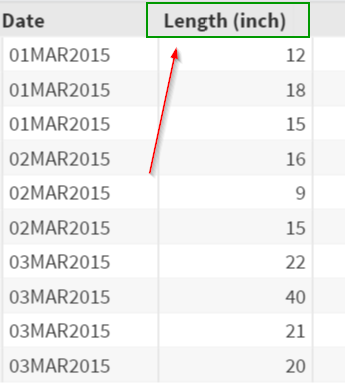
Although the LENGTH variable has a label assigned to it, the PRINT procedure prints the variable name by default.
Example
Proc Print Data=Carrier;
Var Order Length Width Height;
Run;
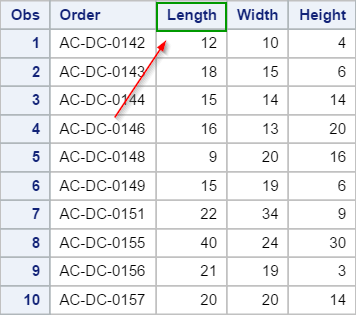
The label of the variable LENGTH isn't displayed in the output.
To display the label instead, simply add the LABEL option to the PRINT procedure.
Example
Proc Print Data=Carrier Label;
Var Order Length Width Height;
Run;

The LABEL option is added to the PRINT option.
The output will display the label as opposed to the variable name.
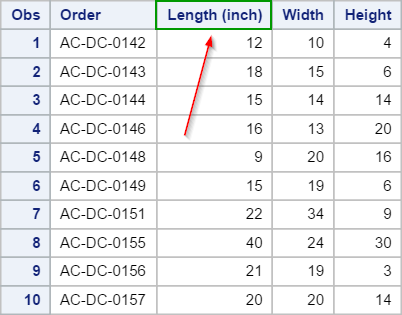
Adding a label in the PRINT procedure
What if the variable isn't assigned a label to begin with?
You can add the label in the PRINT procedure as well.
Example
The WIDTH variable isn't assigned a label:
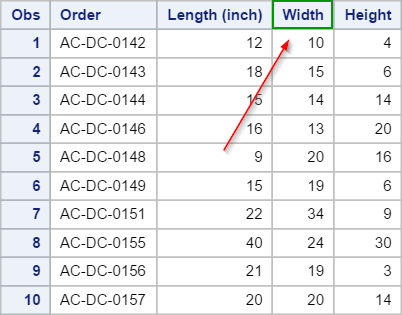
A label can be added to the WIDTH variable with a LABEL statement.
Example
Proc Print Data=Carrier Label;
Var Order Length Width Height;
Label Width = "Width (inch)";
Run;

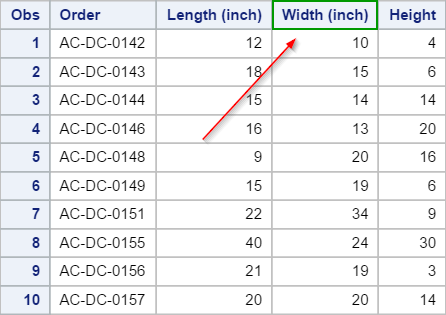
The LABEL statement is added to the PRINT procedure.
The output will display the variable Label instead.
Important Note
When adding the LABEL statement to the PRINT procedure, don't forget to add the LABEL option as well.
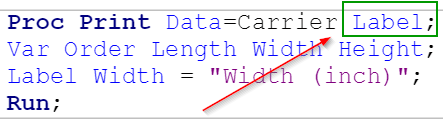
Otherwise, the label wouldn't be displayed in the output despite the present of the LABEL statement.
Exercise
Print the data portion of the CARRIER data set. Display only the following variables:
Add labels to the WIDTH and HEIGHT variables as follows:
- ORDER
- LENGTH
- WIDTH
- HEIGHT
Add labels to the WIDTH and HEIGHT variables as follows:
- WIDTH: Width (inch)
- HEIGHT: Height (inch)
Need some help?
Fill out my online form.